Loi normale et applications
Ce chapitre présente la loi normale, modèle central en probabilités et en statistique. On introduit d’abord la loi normale centrée réduite \(\mathcal{N}(0,1)\), sa densité en cloche et sa fonction de répartition \(\Phi\), puis les règles de calcul associées (symétrie, lecture directe et inverse des probabilités). On généralise ensuite à la loi \(\mathcal{N}(m,\sigma^2)\) et à la standardisation, outil clé pour ramener tout calcul à la table de \(\Phi\). Le chapitre inclut les propriétés fondamentales (espérance, variance, somme de normales indépendantes) et se prolonge par deux applications classiques : la loi log-normale et la loi du khi-deux, et conclut par la loi de Student.
📍 Retour à la carte du cours > Dans tout ce chapitre, nous nous plaçons dans un espace probabilisé quelconque \((\Omega, \mathcal{F}, P)\).
Loi normale centrée réduite \(\mathcal{N}(0,1)\)
Une variable aléatoire réelle \(X\) suit la loi normale centrée réduite, notée \(\mathcal{N}(0,1)\), si sa densité est \[f_X(x) = \frac{1}{\sqrt{2\pi}}\exp\left(-\frac{x^2}{2}\right), \quad x \in \mathbb{R}.\]
Cette densité est positive, intégrée à 1 sur \(\mathbb{R}\), et paire. La courbe de \(f_X\) est donc symétrique par rapport à l’axe des ordonnées. En particulier : \[P(X \leq 0) = P(X \geq 0) = \frac{1}{2}.\]
Le qualificatif « centrée » signifie que l’espérance vaut 0 (la distribution est équilibrée autour de l’origine), et « réduite » signifie que la variance vaut 1 (et donc l’écart-type vaut également 1). La courbe en cloche atteint son maximum en \(x = 0\), présente des points d’inflexion en \(x = \pm 1\), et ses queues décroissent plus vite que toute puissance de \(x\) : la quasi-totalité de la masse est concentrée dans l’intervalle \([-3, 3]\). Bien que la primitive de \(e^{-x^2/2}\) ne soit pas une fonction élémentaire, l’intégrale sur \(\mathbb{R}\) vaut exactement 1 — ce qui s’établit par l’astuce de Poisson (passage en coordonnées polaires d’une intégrale double). La loi \(\mathcal{N}(0,1)\) est la distribution de référence à partir de laquelle toutes les autres lois normales sont déduites par simple changement de localisation et d’échelle.
Si \(X \sim \mathcal{N}(0,1)\), on note \[\Phi(x) = P(X \leq x) = \int_{-\infty}^x \frac{1}{\sqrt{2\pi}}\exp\left(-\frac{t^2}{2}\right)dt.\]
La primitive de \(e^{-t^2/2}\) n’étant pas élémentaire, les valeurs de \(\Phi\) se lisent en pratique dans une table, via calculatrice ou logiciel.
La fonction \(\Phi\) est strictement croissante de 0 à 1 lorsque \(x\) parcourt \(\mathbb{R}\) de \(-\infty\) à \(+\infty\) : \(\Phi(x)\) représente l’aire sous la cloche à gauche du point \(x\), grandeur toujours comprise entre 0 et 1. Par convention, les tables ne donnent \(\Phi\) que pour \(x \geq 0\) ; les valeurs pour \(x < 0\) s’obtiennent grâce à la formule de symétrie \(\Phi(-x) = 1 - \Phi(x)\). L’importance pratique de \(\Phi\) est considérable : tout calcul de probabilité sur une loi normale se ramène à l’évaluation de \(\Phi\) en un ou deux points.
Pour tout réel \(x\) :
- \(\Phi(-x) = 1 - \Phi(x)\),
- \(\Phi(0) = 0{,}5\),
- pour \(x > 0\), \(P(-x \leq X \leq x) = 2\Phi(x) - 1\).
Ces trois propriétés sont les outils de base pour tout calcul sur la loi \(\mathcal{N}(0,1)\). La première, \(\Phi(-x) = 1 - \Phi(x)\), traduit la symétrie de la cloche : l’aire à gauche de \(-x\) égale l’aire à droite de \(x\) ; c’est elle qui permet d’étendre la table (tabulée pour \(x \geq 0\)) aux valeurs négatives. La deuxième, \(\Phi(0) = 0{,}5\), n’est que l’expression de la symétrie globale : la moitié de la masse se trouve de chaque côté de l’origine. La troisième, \(P(-x \leq X \leq x) = 2\Phi(x) - 1\), donne directement la probabilité d’un intervalle symétrique : on double l’aire du côté droit, puis on soustrait la demie-masse centrale.
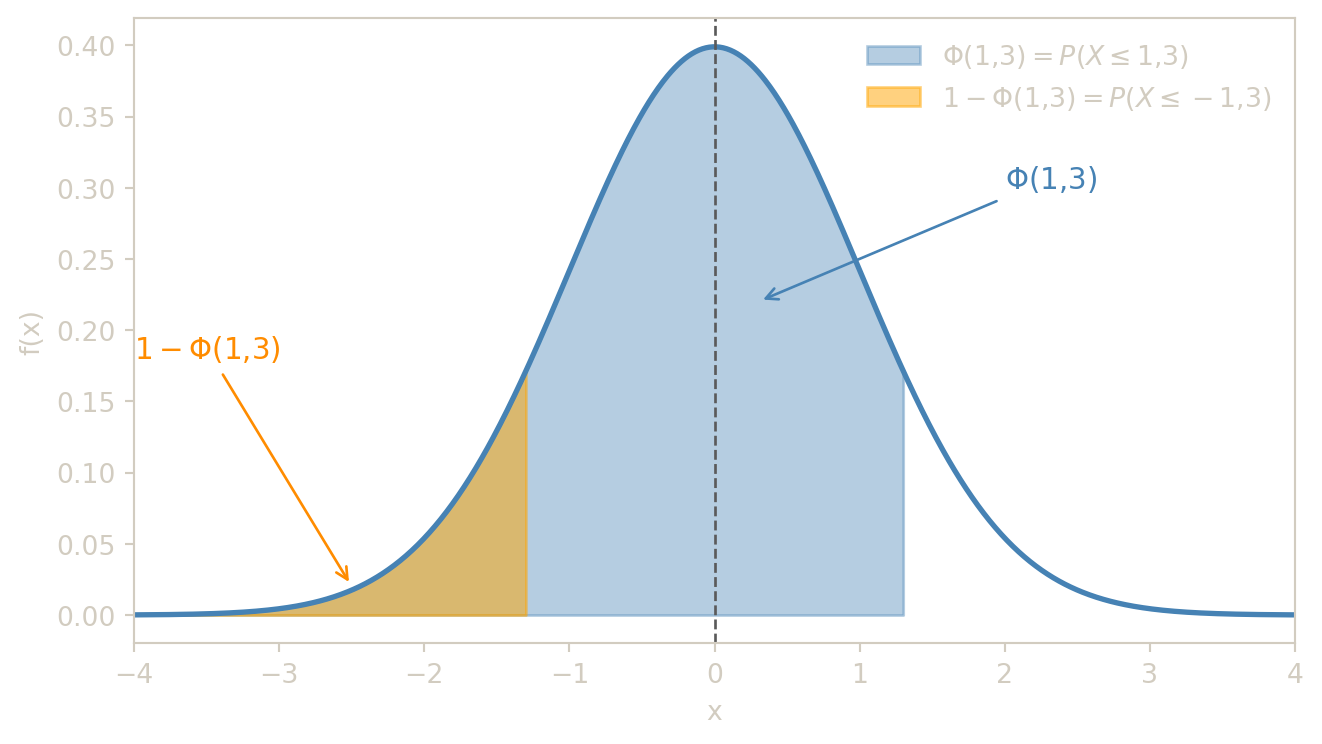
Soit \(X \sim \mathcal{N}(0,1)\).
- Calculer :
- \(P(X \leq 1{,}3)\),
- \(P(X > 0{,}22)\),
- \(P(X < -1{,}57)\),
- \(P(-1{,}5 \leq X \leq 2{,}2)\),
- \(P(-1{,}96 \leq X \leq 1{,}96)\),
- \(P(-2{,}58 \leq X \leq 2{,}58)\).
- Déterminer les réels \(a,b,c,d\) tels que :
- \(P(X \leq a)=0{,}1251\),
- \(P(X > b)=0{,}2327\),
- \(P(0 < X < c)=0{,}4984\),
- \(P(-d \leq X \leq d)=0{,}95\).
La table de \(\Phi\) donne directement les probabilités pour les valeurs positives. Pour les valeurs négatives, on utilise la symétrie : \(\Phi(-x) = 1 - \Phi(x)\). Pour un intervalle \([a, b]\), on écrit \(P(a \leq X \leq b) = \Phi(b) - \Phi(a)\). En lecture inverse, on réécrit l’événement sous la forme \(P(X \leq t) = p\) afin de retrouver \(t = \Phi^{-1}(p)\) dans la table.
Avec la table de \(\Phi\) :
- \(P(X \leq 1{,}3)=\Phi(1{,}3)\approx 0{,}9032\).
- \(P(X > 0{,}22)=1-\Phi(0{,}22)\approx 1-0{,}5871=0{,}4129\).
- \(P(X < -1{,}57)=\Phi(-1{,}57)=1-\Phi(1{,}57)\approx 0{,}0582\).
- \(P(-1{,}5 \leq X \leq 2{,}2)=\Phi(2{,}2)-\Phi(-1{,}5)\approx 0{,}9193\).
- \(P(-1{,}96 \leq X \leq 1{,}96)=2\Phi(1{,}96)-1\approx 0{,}95\).
- \(P(-2{,}58 \leq X \leq 2{,}58)=2\Phi(2{,}58)-1\approx 0{,}9901\).
Lecture inverse :
- \(a \approx -1{,}15\) car \(\Phi(-1{,}15)=0{,}1251\).
- \(b \approx 0{,}73\) car \(1-\Phi(b)=0{,}2327 \iff \Phi(b)=0{,}7673\).
- \(c \approx 2{,}95\) car \(\Phi(c)-0{,}5=0{,}4984 \iff \Phi(c)=0{,}9984\).
- \(d \approx 1{,}96\) car \(2\Phi(d)-1=0{,}95\).
Si \(X \sim \mathcal{N}(0,1)\), alors \[E(X)=0 \quad \text{et} \quad \mathrm{Var}(X)=1.\]
L’espérance \(E(X) = 0\) s’obtient en remarquant que l’intégrande \(x \mapsto x f_X(x)\) est une fonction impaire, dont l’intégrale sur \(\mathbb{R}\) est nulle. La variance \(\mathrm{Var}(X) = E(X^2) = 1\) se calcule par une intégration par parties qui ramène \(\int x^2 e^{-x^2/2} dx\) à l’intégrale gaussienne usuelle. Ces deux valeurs justifient la terminologie : « centrée » pour \(E(X)=0\) et « réduite » pour \(\mathrm{Var}(X)=1\) (soit un écart-type égal à 1). La loi \(\mathcal{N}(0,1)\) est ainsi le représentant canonique de la famille des lois normales, à partir duquel tous les autres se déduisent par transformation linéaire.
Soit \(X \sim \mathcal{N}(0,1)\).
- Calculer les probabilités suivantes :
- \(P(X < 1{,}23)\),
- \(P(X > 0{,}96)\),
- \(P(-2{,}05 < X < 1)\),
- \(P(X^2 < 1{,}44)\).
- Déterminer \(k\) dans les cas suivants :
- \(P(X < k) = 0{,}7\),
- \(P(X > k) = 0{,}962\),
- \(P(|X| > k) = 0{,}6\).
Utiliser directement la table de \(\Phi\) et les relations : \(P(X>a)=1-\Phi(a)\), \(P(-a<X<a)=2\Phi(a)-1\), \(P(X^2<c)=P(-\sqrt{c}<X<\sqrt{c})\).
Loi normale générale \(\mathcal{N}(m,\sigma^2)\)
Soient \(m \in \mathbb{R}\) et \(\sigma > 0\). On dit que \(X\) suit la loi normale \(\mathcal{N}(m,\sigma^2)\) si sa densité est \[f_X(x)=\frac{1}{\sigma\sqrt{2\pi}}\exp\left(-\frac{(x-m)^2}{2\sigma^2}\right), \quad x\in\mathbb{R}.\]
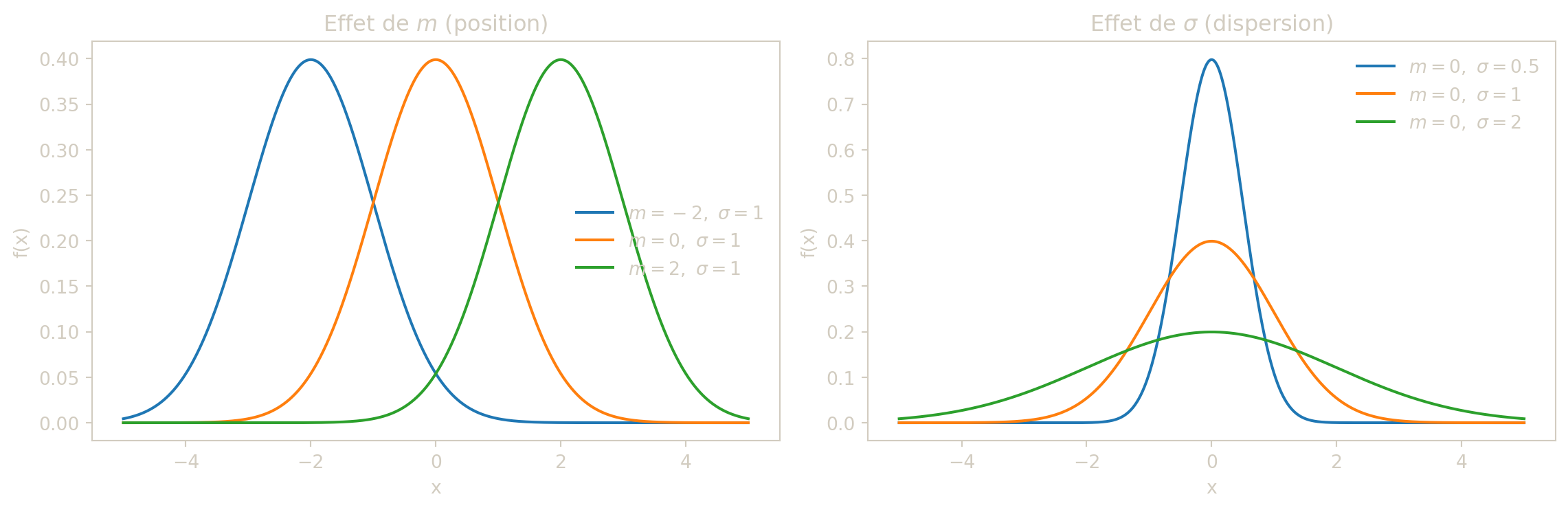
Ici, \(m\) est le paramètre de position (centre), et \(\sigma\) contrôle la dispersion autour de \(m\).
Le paramètre \(m\) déplace la courbe en cloche vers la gauche ou vers la droite sans en modifier la forme ; \(\sigma\) en change l’échelle : un grand \(\sigma\) donne une courbe aplatie et étalée, un petit \(\sigma\) donne une courbe étroite et pointue. Le maximum de \(f_X\) est atteint en \(x = m\) (c’est aussi le mode et la médiane), et les points d’inflexion se trouvent en \(x = m \pm \sigma\). Le facteur \(\frac{1}{\sigma\sqrt{2\pi}}\) assure la normalisation : quelle que soient \(m \in \mathbb{R}\) et \(\sigma > 0\), l’intégrale de \(f_X\) sur \(\mathbb{R}\) vaut exactement 1. Enfin, si \(Z \sim \mathcal{N}(0,1)\), alors \(X = m + \sigma Z\) suit \(\mathcal{N}(m, \sigma^2)\) : la loi générale n’est qu’une version décalée et redimensionnée de la loi centrée réduite.
Si \(X \sim \mathcal{N}(m,\sigma^2)\), alors la variable \[Z=\frac{X-m}{\sigma}\] suit \(\mathcal{N}(0,1)\).
Réciproquement, si \(Z \sim \mathcal{N}(0,1)\), alors \(X=m+\sigma Z\) suit \(\mathcal{N}(m,\sigma^2)\).
Cette proposition est l’outil central de calcul : toute probabilité sur une loi normale se ramène à une lecture de \(\Phi\).
Géométriquement, standardiser revient à re-centrer la distribution en 0 et à la comprimer ou dilater pour que son écart-type vaille 1 : on passe ainsi de n’importe quelle loi \(\mathcal{N}(m, \sigma^2)\) à la loi de référence \(\mathcal{N}(0,1)\). Grâce à cette transformation, une seule table (celle de \(\Phi\)) suffit pour calculer des probabilités sur toutes les lois normales. Le schéma de calcul est le suivant : \(P(X \leq a) = P\!\left(Z \leq \dfrac{a - m}{\sigma}\right) = \Phi\!\left(\dfrac{a - m}{\sigma}\right)\). La quantité \(\dfrac{a - m}{\sigma}\) est appelée la valeur centrée réduite (ou z-score) de \(a\) : elle indique de combien d’écarts-types \(a\) se trouve au-dessus (ou en dessous) de la moyenne \(m\). Cette transformation est linéaire, ce qui préserve la normalité et rend la standardisation exacte (et non approximative).
- Soit \(X \sim \mathcal{N}(30,9)\). Calculer :
- \(P(X>36)\),
- \(P(25 \leq X \leq 35)\).
- Soit \(X \sim \mathcal{N}(90,400)\). Déterminer :
- \(k\) tel que \(P(X<k)=0{,}9798\),
- \(k'\) tel que \(P(X>k')=0{,}6026\),
- un intervalle \(I\) centré en 90 tel que \(P(X\in I)=0{,}85\).
La méthode universelle est la standardisation : on pose \(Z = (X-m)/\sigma\), qui suit \(\mathcal{N}(0,1)\), et on se ramène à une lecture de \(\Phi\). Pour les problèmes inverses, on isole d’abord le quantile de \(Z\) dans la table, puis on retrouve la valeur de \(X\) en appliquant \(X = m + \sigma Z\).
1. \(X \sim \mathcal{N}(30,9)\) donc \(\sigma=3\) et \(Z=(X-30)/3 \sim \mathcal{N}(0,1)\).
- \(P(X>36)=P\!\left(Z>\frac{36-30}{3}\right)=P(Z>2)=1-\Phi(2)\approx 0{,}0228\).
- \(P(25 \leq X \leq 35)=P\!\left(-\frac{5}{3} \leq Z \leq \frac{5}{3}\right) \approx 2\Phi(1{,}67)-1 \approx 0{,}9044\).
2. \(X \sim \mathcal{N}(90,400)\) donc \(\sigma=20\).
- \(P(X<k)=0{,}9798 \Rightarrow \dfrac{k-90}{20}=2{,}05\), donc \(k=131\).
- \(P(X>k')=0{,}6026 \Rightarrow P(X\leq k')=0{,}3974\), donc \(\dfrac{k'-90}{20}\approx -0{,}26\) et \(k'\approx 84{,}8\).
- On cherche \(I=[90-a,90+a]\) avec \(P(|X-90|\leq a)=0{,}85\). En standardisant : \(P(|Z|\leq a/20)=0{,}85\), donc \(2\Phi(a/20)-1=0{,}85\), d’où \(\Phi(a/20)=0{,}925\) et \(a/20\approx 1{,}44\). Ainsi \(a\approx 28{,}8\), et \(I\approx[61{,}2\,;\,118{,}8]\).
Soit \(X \sim \mathcal{N}(1,0{,}5^2)\).
- Calculer \(P(X < 1{,}91)\), \(P(X > 0{,}82)\) et \(P(0{,}82 < X < 1{,}91)\).
- Trouver \(t\) tel que :
- \(P(X < t) = 0{,}670\),
- \(P(X \ge t) = 0{,}791\),
- \(P(|X-1| < t) = 0{,}866\).
Standardiser avec \(Z=\dfrac{X-1}{0{,}5}\), puis revenir à \(X\) via \(t=1+0{,}5z\).
Soit \(X \sim \mathcal{N}(m,\sigma^2)\).
Calculer : - \(P(|X-m|<\sigma)\), - \(P(|X-m|<2\sigma)\), - \(P(|X-m|<3\sigma)\).
Arrondir à \(10^{-3}\) près.
On pose \(Z = \dfrac{X-m}{\sigma} \sim \mathcal{N}(0,1)\). Alors pour tout \(k > 0\) : \[P(|X - m| < k\sigma) = P(|Z| < k) = 2\Phi(k) - 1.\]
- \(P(|X-m| < \sigma) = 2\Phi(1) - 1 \approx 2 \times 0{,}8413 - 1 = 0{,}683\).
- \(P(|X-m| < 2\sigma) = 2\Phi(2) - 1 \approx 2 \times 0{,}9772 - 1 = 0{,}954\).
- \(P(|X-m| < 3\sigma) = 2\Phi(3) - 1 \approx 2 \times 0{,}9987 - 1 = 0{,}997\).
Soit \(X\) une variable aléatoire.
- Si \(X \sim \mathcal{N}(10,4)\), calculer \(P(X<14)\).
- Si \(X \sim \mathcal{N}(0,1)\), calculer \(P(|X-1|>0{,}5)\).
- Si \(X \sim \mathcal{N}(1,4)\), déterminer \(a>0\) tel que \(P(|X-1|>a)\le 0{,}03\).
Pour la question 3 : \(P(|X-1|>a)\le 0{,}03 \iff P(|Z|\le a/2)\ge 0{,}97\), avec \(Z\sim\mathcal{N}(0,1)\).
Si \(X \sim \mathcal{N}(m,\sigma^2)\), alors \[E(X)=m \quad \text{et} \quad \mathrm{Var}(X)=\sigma^2.\]
Ces résultats confirment l’interprétation des paramètres : \(m\) est bien le centre de masse (l’espérance) et \(\sigma\) est l’écart-type, mesure directe de la dispersion typique de \(X\) autour de sa moyenne. On les obtient à partir du cas \(\mathcal{N}(0,1)\) par la transformation linéaire \(X = m + \sigma Z\) : \(E(X) = m + \sigma \cdot E(Z) = m\) et \(\mathrm{Var}(X) = \sigma^2 \cdot \mathrm{Var}(Z) = \sigma^2\). Ces formules sont cohérentes avec le cas particulier \(\mathcal{N}(0,1)\) où \(m = 0\) et \(\sigma = 1\), et elles montrent que les paramètres de la loi ont une signification statistique immédiate et intuitive.
Pour toute variable \(X \sim \mathcal{N}(m,\sigma^2)\), la standardisation donne immédiatement :
\[P(|X-m| < \sigma) \approx 0{,}683, \qquad P(|X-m| < 2\sigma) \approx 0{,}954, \qquad P(|X-m| < 3\sigma) \approx 0{,}997.\]
Autrement dit, environ 68 % des valeurs se trouvent à moins d’un écart-type de la moyenne, 95 % à moins de deux écarts-types et 99,7 % à moins de trois écarts-types. Cette règle des trois sigma fournit un repère mental rapide pour apprécier la « normalité » d’une observation : une valeur au-delà de \(3\sigma\) est exceptionnelle (moins de 0,3 % de chances).
Si \(X_1,\dots,X_n\) sont indépendantes et \(X_i\sim\mathcal{N}(m_i,\sigma_i^2)\), alors \[Y=\sum_{i=1}^n X_i \sim \mathcal{N}\left(\sum_{i=1}^n m_i,\sum_{i=1}^n \sigma_i^2\right).\]
Cette propriété de stabilité signifie que la famille des lois normales est fermée par addition de variables indépendantes : une somme de normales indépendantes reste normale. La nouvelle espérance est la somme des espérances (par linéarité), et la nouvelle variance est la somme des variances (par indépendance). Attention : ce sont bien les variances qui s’additionnent, et non les écarts-types. Cette propriété est fondamentale en pratique pour modéliser la somme de nombreuses contributions indépendantes (erreurs de mesure, fluctuations aléatoires, etc.). Le résultat est « admis » car sa démonstration fait appel aux fonctions caractéristiques ou à la convolution des densités, outils qui dépassent le cadre de ce cours.
Lors d’un test, 70 % des individus ont un score inférieur à 60. On suppose une loi normale d’écart-type 20. Déterminer l’espérance \(m\).
Il s’agit d’un problème inverse : on connaît la probabilité et on cherche le paramètre \(m\). Après standardisation, la condition \(P(X \leq 60) = 0{,}70\) signifie que la valeur standardisée \(\dfrac{60-m}{20}\) doit coïncider avec le quantile d’ordre \(0{,}70\) de \(\mathcal{N}(0,1)\), que l’on lit dans la table de \(\Phi\).
Si \(X\sim\mathcal{N}(m,20^2)\) et \(P(X\leq 60)=0{,}70\), alors \[\frac{60-m}{20}=z_{0{,}70}\approx 0{,}5244.\] Donc \[m \approx 60-20\times 0{,}5244 \approx 49{,}5.\]
Soit \(X \sim \mathcal{N}(m,\sigma^2)\).
- Sachant que \(\mathrm{Var}(X)=4\) et \(P(X>2)=0{,}4\), calculer \(E(X)\).
- Sachant que \(E(X)=-2{,}56\) et \(P(X<0)=0{,}9\), calculer \(\mathrm{Var}(X)\).
Écrire chaque condition sous la forme \(\Phi\!\left(\dfrac{x_0-m}{\sigma}\right)=p\) puis utiliser la table inverse.
Un lot contient des pièces défectueuses dont le nombre aléatoire \(X\) suit une loi \(\mathcal{N}(m,\sigma^2)\).
On sait que : - \(P(X\le 204)=0{,}58\), - \(P(X\ge 235)=0{,}04\).
Déterminer \(m\) et \(\sigma\).
Transformer en : \(\dfrac{204-m}{\sigma}=z_{0{,}58}\) et \(\dfrac{235-m}{\sigma}=z_{0{,}96}\), puis résoudre le système à deux inconnues.
Dans la ville de Prairie, la taille \(X\) des individus (en cm) suit une loi \(\mathcal{N}(m,\sigma^2)\).
On observe que : - 30,85 % des individus mesurent moins de 165 cm, - 15,87 % mesurent plus de 180 cm.
Déterminer \(m\) et \(\sigma\).
Utiliser : \(\Phi\!\left(\dfrac{165-m}{\sigma}\right)=0{,}3085\) et \(\Phi\!\left(\dfrac{180-m}{\sigma}\right)=0{,}8413\).
Soient \(X\) et \(Y\) indépendantes de loi \(\mathcal{N}(0,2)\). Calculer \(P(X+Y\leq 1)\).
La propriété de stabilité de la loi normale garantit que la somme de variables aléatoires normales indépendantes est encore une variable normale. Il suffit donc d’additionner les espérances et les variances (et non les écarts-types) pour identifier la loi de \(X+Y\).
Par stabilité de la loi normale, \[X+Y \sim \mathcal{N}(0,4).\] Donc \[P(X+Y\leq 1)=P\left(\frac{X+Y}{2}\leq \frac12\right)=\Phi(0{,}5)\approx 0{,}6915.\]
Soit \(X \sim \mathcal{N}(20,4)\). On pose : - \(Y=50X\), - \(Z=\sum_{i=1}^{50} X_i\) où les \(X_i\) sont indépendantes et de même loi que \(X\), - \(W=\dfrac{Z}{50}\).
Déterminer la loi de \(Y\), \(Z\) et \(W\).
Utiliser : - la transformation affine d’une normale, - la stabilité par somme de normales indépendantes.
Un étudiant passe un examen comportant deux épreuves de même coefficient, notées indépendantes \(X\) et \(Y\) avec : - \(X \sim \mathcal{N}(12,2)\), - \(Y \sim \mathcal{N}(13,5)\).
- Déterminer la loi de la moyenne \(Z=\dfrac{X+Y}{2}\).
- Calculer \(P(Z\ge 10)\).
- Déterminer un intervalle centré sur \(E(Z)\) contenant \(Z\) avec probabilité 0,9.
- Calculer \(P(X\ge 10\ \text{et}\ Y\ge 10)\).
- Une mention est attribuée si \(Z\ge 14\) et si aucune note n’est en dessous de 10. Calculer la probabilité d’obtenir la mention.
- Question 4 : utiliser l’indépendance, \(P(X\ge 10, Y\ge 10)=P(X\ge 10)P(Y\ge 10)\).
- Question 5 : l’événement est \(\{Z\ge 14\}\cap\{X\ge 10\}\cap\{Y\ge 10\}\).
Une entreprise reçoit un chargement de 100 wagons de céréales. Les masses transportées (en tonnes) sont des v.a.r. indépendantes \(M_i\) suivant la loi \(\mathcal{N}(55,0{,}25)\).
- Déterminer la loi de la masse totale \(M_T=\sum_{i=1}^{100} M_i\).
- Déterminer la loi de la masse moyenne \(\overline{M}=\dfrac{1}{100}\sum_{i=1}^{100}M_i\).
- Déterminer \(a>0\) tel que \(P\big(\overline{M}\in[55-a\,;\,55+a]\big)>0{,}95\).
\(\overline{M}\) est normale de moyenne 55 et de variance \(0{,}25/100\). Ramener ensuite à \(P(|Z|\le z_{0{,}975})\).
Soit \(X \sim \mathcal{N}(1,4)\) et \(Y=2X+1\).
- Déterminer la loi de \(Y\).
- Calculer \(E(Y^2)\).
Utiliser \(E(Y^2)=\mathrm{Var}(Y)+E(Y)^2\).
Soient \(X \sim \mathcal{N}(m,\sigma^2)\) et \(b>0\). Déterminer \(x\) tel que \(P(x<X<x+b)\) soit maximale.
(On pourra étudier \(f(x)=P(x<X<x+b)\).)
On pose \(f(x) = P(x < X < x + b) = F_X(x+b) - F_X(x)\), où \(F_X\) est la fonction de répartition de \(X\).
La fonction \(f\) est dérivable et : \[f'(x) = f_X(x+b) - f_X(x),\] où \(f_X\) est la densité de \(X \sim \mathcal{N}(m, \sigma^2)\).
On cherche \(f'(x) = 0\), c’est-à-dire \(f_X(x+b) = f_X(x)\).
Comme la densité normale est symétrique par rapport à \(m\), l’égalité \(f_X(x+b) = f_X(x)\) impose que \(x\) et \(x+b\) soient symétriques par rapport à \(m\) : \[\frac{x + (x+b)}{2} = m \implies x = m - \frac{b}{2}.\]
On vérifie que c’est bien un maximum : c’est le seul point critique, et \(f(x) \to 0\) quand \(x \to \pm \infty\).
Conclusion : la probabilité \(P(x < X < x+b)\) est maximale pour \(x = m - \dfrac{b}{2}\), c’est-à-dire lorsque l’intervalle \(]x, x+b[\) est centré en \(m\).
Soient \(X \sim \mathcal{N}(m,\sigma^2)\) et \(Y=aX+b\) avec \((a,b)\in\mathbb{R}^*\times\mathbb{R}\).
- Calculer \(E(Y)\) et \(\mathrm{Var}(Y)\).
- Montrer que \(Y \sim \mathcal{N}(am+b, a^2\sigma^2)\).
Montrer que \(\dfrac{Y-(am+b)}{|a|\sigma}=\operatorname{sgn}(a)\dfrac{X-m}{\sigma}\), puis utiliser l’invariance de la loi de \(Z\sim\mathcal{N}(0,1)\) par symétrie.
Soient \(X \sim \mathcal{N}(0,1)\) et \(U\) une v.a.r. telle que \(P(U=1)=P(U=-1)=0{,}5\).
En supposant \(X\) et \(U\) indépendantes, déterminer la loi de \(Z=XU\).
Conditionner par \(U=1\) et \(U=-1\). Comparer les lois de \(X\) et \(-X\).
Application : loi log-normale
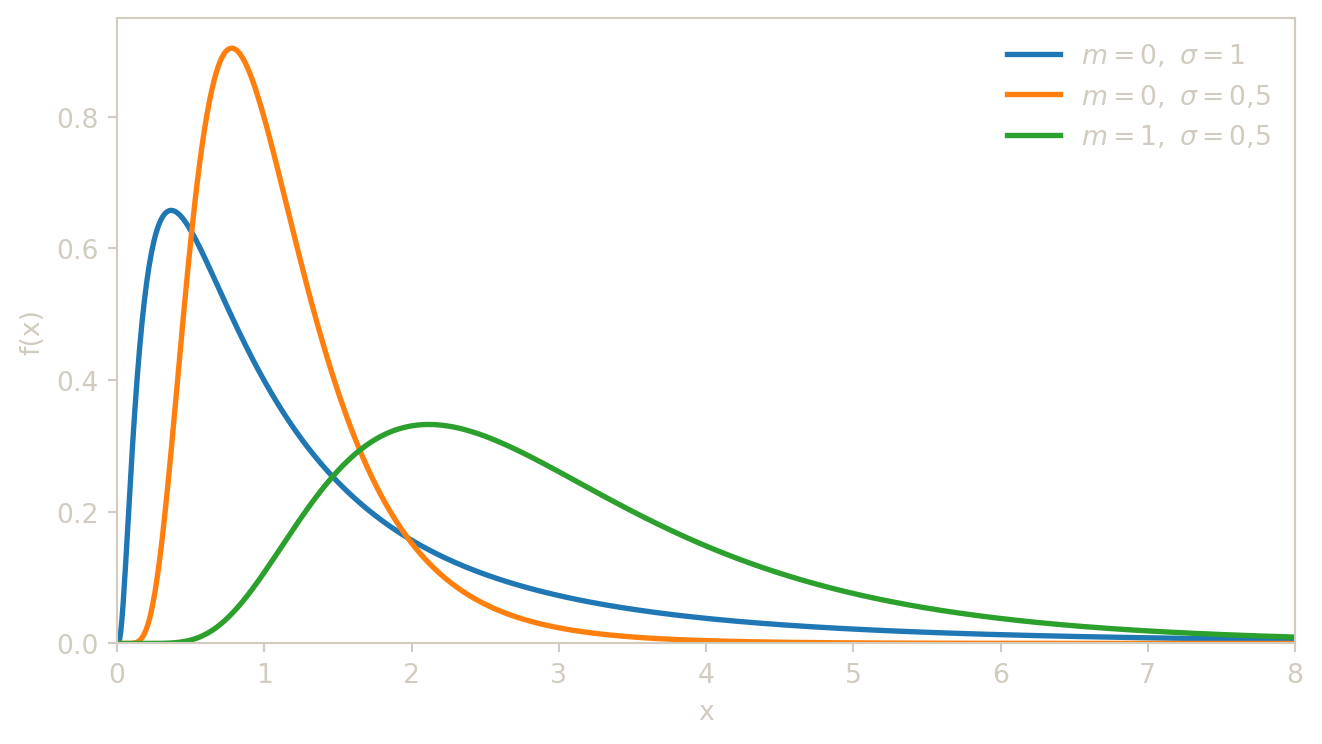
On dit que \(X\) suit une loi log-normale de paramètres \(m\in\mathbb{R}\) et \(\sigma>0\) si \[\ln(X)\sim\mathcal{N}(m,\sigma^2).\] En particulier, \(X>0\) presque sûrement.
De nombreuses quantités réelles sont strictement positives et ont un logarithme qui suit approximativement une loi normale : c’est le cas des prix d’actifs financiers, des tailles biologiques ou encore de certains revenus. Si \(\ln(X) \sim \mathcal{N}(m, \sigma^2)\), alors \(X = e^{\ln X}\) est obtenu en appliquant l’exponentielle à une variable normale, ce qui garantit \(X > 0\) presque sûrement. Il est important de noter que \(m\) et \(\sigma\) sont la moyenne et l’écart-type de \(\ln(X)\), et non de \(X\) lui-même : l’espérance de \(X\) vaut \(e^{m + \sigma^2/2}\), qui est toujours supérieure à \(e^m\) en raison de la convexité de l’exponentielle (inégalité de Jensen). Cette différence entre la moyenne et la médiane (qui vaut \(e^m\)) reflète l’asymétrie à droite caractéristique de la loi log-normale.
Si \(X\) est log-normale de paramètres \((m,\sigma)\), alors pour \(x>0\) : \[f_X(x)=\frac{1}{x\sigma\sqrt{2\pi}}\exp\left(-\frac{1}{2}\left(\frac{\ln x-m}{\sigma}\right)^2\right).\]
De plus, \[E(X)=e^{m+\sigma^2/2}, \qquad \mathrm{Var}(X)=e^{2m+\sigma^2}(e^{\sigma^2}-1).\]
Dans la formule de densité, le facteur \(1/x\) provient du changement de variable \(x \mapsto \ln x\) (jacobien de la transformation), et le reste n’est autre que la densité \(\mathcal{N}(m, \sigma^2)\) évaluée en \(\ln x\). La clé pour les calculs de probabilités est la relation \(P(X \leq a) = P(\ln X \leq \ln a) = \Phi\!\left(\dfrac{\ln a - m}{\sigma}\right)\), qui ramène tout calcul à une évaluation de \(\Phi\) après une simple transformation logarithmique. L’espérance \(E(X) = e^{m + \sigma^2/2}\) est strictement supérieure à la médiane \(e^m\) : la distribution est asymétrique à droite, avec quelques très grandes valeurs qui tirent la moyenne vers le haut.
Soit \(X\) log-normale de paramètres \(m=1\) et \(\sigma=1\). Calculer \(P(X>1)\).
L’idée clé est la transformation logarithmique : puisque \(\ln(X) \sim \mathcal{N}(1,1)\), tout événement portant sur \(X\) se traduit immédiatement en événement sur une variable normale. En particulier, \(P(X > 1) = P(\ln X > \ln 1) = P(\ln X > 0)\), ce qui ramène le calcul à la loi \(\mathcal{N}(1,1)\) puis, après standardisation, à \(\Phi\).
Comme \(\ln(X)\sim\mathcal{N}(1,1)\), \[P(X>1)=P(\ln(X)>0)=P(Z>-1)=\Phi(1)\approx 0{,}8413.\]
Soit \(Y\) une v.a.r. suivant une loi log-normale de paramètres \(m\) et \(\sigma\), c’est-à-dire telle que \(X=\ln(Y)\sim\mathcal{N}(m,\sigma^2)\).
- Cas \(m=3\), \(\sigma=2\) : calculer \(P(1\le Y\le e^5)\).
- Cas général :
- déterminer une densité de \(Y\),
- en admettant \(X=m+\sigma Z\) avec \(Z\sim\mathcal{N}(0,1)\), montrer que \(E(Y)=e^m E(e^{\sigma Z})\),
- en déduire \(E(Y)\) et \(\mathrm{Var}(Y)\),
- déterminer la loi de \(W=\dfrac{1}{Y}\).
- Pour la densité : dériver \(F_Y(y)=P(X\le\ln y)\) pour \(y>0\).
- Pour \(W=1/Y\), remarquer que \(\ln(W)=-\ln(Y)\).
Dans certains modèles financiers, le cours futur d’une action est : \[S_T=S_0e^X,\] où \(S_0>0\) et \(X\sim\mathcal{N}(m,\sigma^2)\).
- Justifier que \(S_T\) suit une loi log-normale et en donner les paramètres.
- Vérifier que \(E(S_T)=S_0 \iff m=-\dfrac{\sigma^2}{2}\).
- Exprimer alors \(\mathrm{Var}(S_T)\) en fonction de \(\sigma\) et \(S_0\).
Utiliser \(E(e^X)=e^{m+\sigma^2/2}\) et \(\mathrm{Var}(S_T)=S_0^2\mathrm{Var}(e^X)\).
Application : loi du khi-deux
Si \(Z\sim\mathcal{N}(0,1)\), alors \(Y=Z^2\) suit la loi du khi-deux à 1 degré de liberté, notée \(\chi^2_1\).
Élever une variable au carré ne peut donner qu’un résultat positif, ce qui explique que \(\chi^2_1\) soit une loi sur \((0, +\infty)\). Par symétrie de la loi \(\mathcal{N}(0,1)\), les valeurs \(Z\) et \(-Z\) produisent le même carré : la droite réelle se « replie » sur la demi-droite positive, concentrant en particulier de la masse près de 0. Cette loi apparaît naturellement en statistique dès que l’on calcule un carré de résidu ou un carré d’écart-type empirique, et constitue le fondement de la loi du khi-deux à \(n\) degrés de liberté.
La densité de \(Y\sim\chi^2_1\) est, pour \(x>0\), \[f_Y(x)=\frac{1}{\sqrt{2\pi}}x^{-1/2}e^{-x/2},\] et \[E(Y)=1, \qquad \mathrm{Var}(Y)=2.\]
L’espérance \(E(Y) = 1\) s’obtient immédiatement : \(Y = Z^2\) et \(E(Z^2) = \mathrm{Var}(Z) = 1\) pour \(Z \sim \mathcal{N}(0,1)\). La variance \(\mathrm{Var}(Y) = 2\) nécessite de calculer \(E(Z^4) = 3\) (moment d’ordre 4 de la loi normale), ce qui donne \(\mathrm{Var}(Z^2) = E(Z^4) - (E(Z^2))^2 = 3 - 1 = 2\). La densité \(f_Y\) est singulière en \(x = 0\) (elle tend vers \(+\infty\)) car le repliement de la droite réelle concentre une densité importante de masse près de 0, correspondant aux valeurs de \(Z\) proches de 0 de part et d’autre.
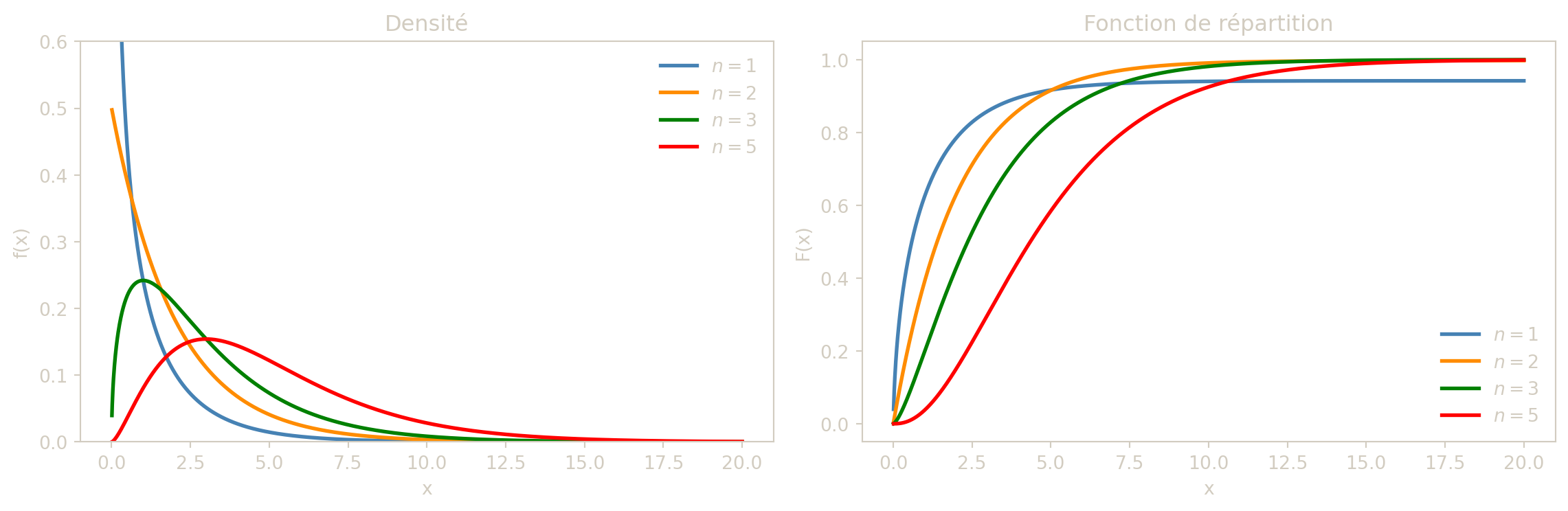
Si \(Z_1,\dots,Z_n\) sont indépendantes et suivent toutes \(\mathcal{N}(0,1)\), alors \[X=\sum_{i=1}^n Z_i^2\] suit la loi \(\chi^2_n\).
La loi \(\chi^2_n\) est donc une somme de \(n\) variables indépendantes \(\chi^2_1\), ce qui en fait une généralisation naturelle du cas \(n = 1\). L’entier \(n\) est appelé le degré de liberté ; il contrôle la forme de la distribution : pour de petites valeurs de \(n\), la loi est fortement asymétrique à droite, tandis que pour de grandes valeurs de \(n\), elle s’approche d’une loi normale (par le théorème central limite). En statistique, \(\chi^2_n\) apparaît très naturellement comme la loi de la somme de \(n\) carrés de résidus standardisés, par exemple dans les tests d’indépendance sur des tableaux de contingence ou dans les tests d’ajustement.
La densité de la loi \(\chi^2_n\) fait appel à la fonction Gamma d’Euler. Pour \(x > 0\) : \[f_X(x) = \frac{1}{2^{n/2}\,\Gamma(n/2)}\,x^{(n-2)/2}\,e^{-x/2}\,\mathbf{1}_{]0,+\infty[}(x),\] où \(\Gamma\) est définie par \(\Gamma(s) = \displaystyle\int_0^{+\infty} t^{s-1}e^{-t}\,dt\) pour \(s > 0\).
On retrouve la densité de \(\chi^2_1\) en posant \(n=1\) et en utilisant \(\Gamma(1/2) = \sqrt{\pi}\).
Si \(X\sim\chi^2_n\), alors \[E(X)=n \qquad \text{et} \qquad \mathrm{Var}(X)=2n.\]
L’espérance \(E(X) = n\) découle directement de la linéarité : \(X\) est la somme de \(n\) variables indépendantes \(Y_i \sim \chi^2_1\), chacune d’espérance 1, donc \(E(X) = n \cdot 1 = n\). De même, par indépendance, \(\mathrm{Var}(X) = n \cdot \mathrm{Var}(Y_i) = n \cdot 2 = 2n\). Lorsque \(n\) grandit, la moyenne croît linéairement tandis que l’écart-type ne croît qu’en \(\sqrt{2n}\) : le coefficient de variation \(\sigma/\mu = \sqrt{2n}/n \to 0\), ce qui signifie que la distribution se concentre relativement de plus en plus autour de sa moyenne. C’est précisément pourquoi, pour de grands degrés de liberté, la loi \(\chi^2_n\) est bien approchée par une loi normale.
Soit \(X\sim\chi^2_7\). À l’aide de la table :
- Calculer :
- \(P(X<4{,}255)\),
- \(P(X\geq 9{,}037)\),
- \(P(2{,}167\leq X\leq 12{,}02)\).
- Déterminer \(x\) tel que \(P(X<x)=0{,}1\).
La table du \(\chi^2\) donne des quantiles : pour chaque degré de liberté \(n\), elle fournit des valeurs \(x\) telles que \(P(X < x) = p\) pour des probabilités \(p\) usuelles. La lecture est donc l’inverse de la table normale : on repère \(x\) dans le corps du tableau pour retrouver \(p\), ou on repère \(p\) pour retrouver \(x\) (lecture inverse). Pour \(n=7\), on lit directement les valeurs souhaitées dans la ligne correspondante.
Pour \(n=7\), la table donne approximativement :
- \(F(4{,}255)=0{,}25\),
- \(F(9{,}037)=0{,}75\),
- \(F(2{,}167)=0{,}10\),
- \(F(12{,}02)=0{,}90\).
Donc :
- \(P(X<4{,}255)=0{,}25\),
- \(P(X\geq 9{,}037)=1-0{,}75=0{,}25\),
- \(P(2{,}167\leq X\leq 12{,}02)=0{,}90-0{,}10=0{,}80\),
- le quantile d’ordre 0,1 vaut \(x=2{,}167\).
Soit \(X\sim\chi^2_3\).
- Déterminer :
- \(P(X>7{,}815)\),
- \(P(2{,}366<X<4{,}108)\).
- Démontrer que \(E(X)=3\) et \(\mathrm{Var}(X)=6\).
- Question 1 : utiliser la table de la loi du khi-deux.
- Question 2 : écrire \(X=Z_1^2+Z_2^2+Z_3^2\) avec \(Z_i\sim\mathcal{N}(0,1)\) indépendantes.
Application : loi de Student
Soient \(X\) et \(Y\) deux variables aléatoires indépendantes avec \(X \sim \mathcal{N}(0,1)\) et \(Y \sim \chi^2_n\).
La variable aléatoire \[T_n = \frac{X}{\sqrt{Y/n}}\] suit la loi de Student à \(n\) degrés de liberté, notée \(\mathcal{T}_n\) (ou \(t_n\)).
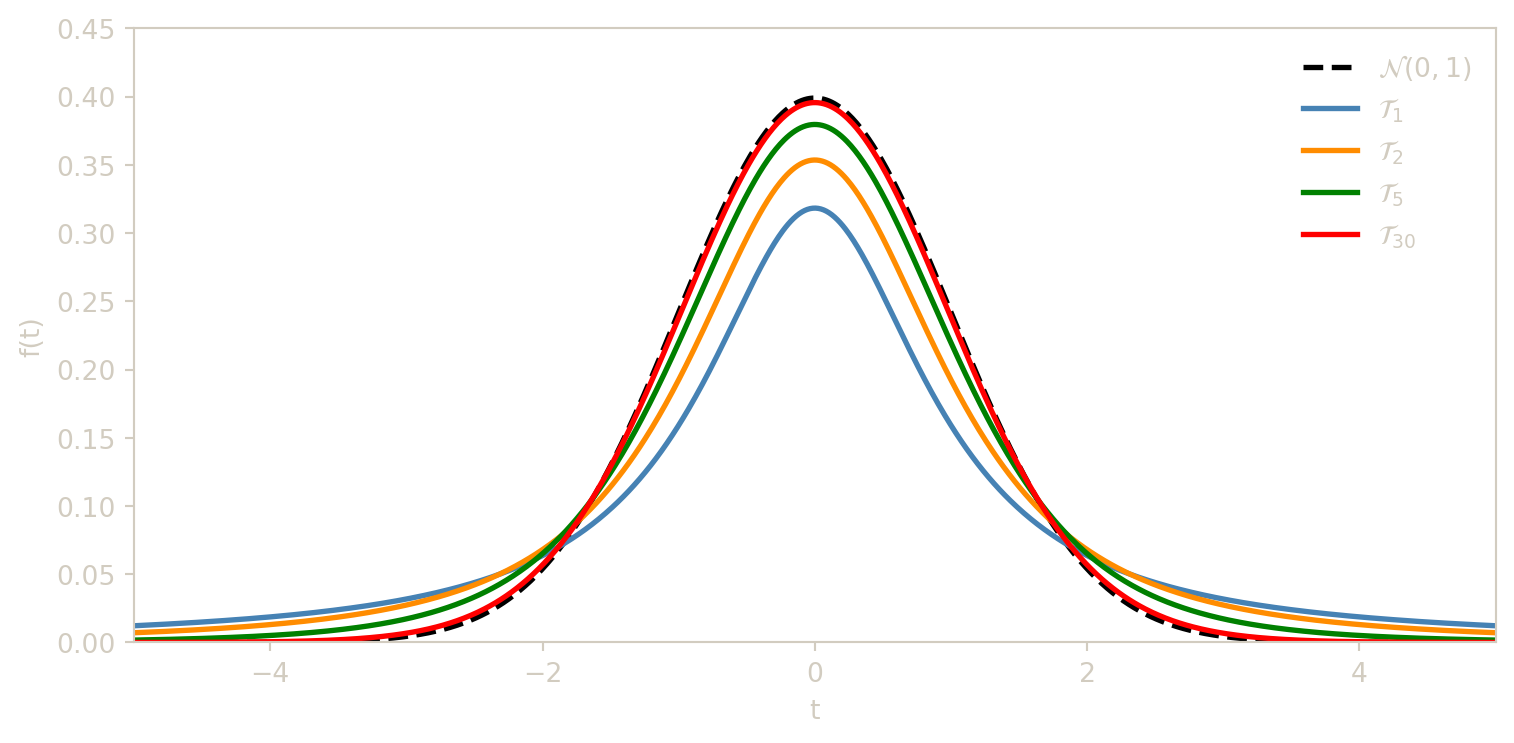
La loi de Student porte le nom du pseudonyme « Student » utilisé par William Sealy Gosset (1876–1937), statisticien à la brasserie Guinness, qui a publié cette distribution en 1908. Elle apparaît naturellement en statistique lorsqu’on estime la moyenne d’une population normale en remplaçant l’écart-type théorique \(\sigma\) par l’écart-type empirique \(S_n\) : le rapport résultant suit une loi de Student et non une loi normale. Le paramètre \(n\) (degrés de liberté) contrôle l’épaisseur des queues : plus \(n\) est petit, plus les queues sont lourdes, reflétant l’incertitude supplémentaire due à l’estimation de \(\sigma\).
La densité de la loi de Student à \(n\) degrés de liberté est, pour \(t \in \mathbb{R}\) : \[f_{T_n}(t) = \frac{\Gamma\!\left(\frac{n+1}{2}\right)}{\sqrt{n\pi}\;\Gamma\!\left(\frac{n}{2}\right)}\left(1+\frac{t^2}{n}\right)^{-(n+1)/2},\] où \(\Gamma\) est la fonction Gamma d’Euler. Cette densité est symétrique par rapport à \(0\) et ressemble à la cloche de Gauss, mais avec des queues plus épaisses.
Soit \(T_n \sim \mathcal{T}_n\).
- Si \(n \geq 2\) : \(\;E(T_n) = 0\).
- Si \(n \geq 3\) : \(\;\mathrm{Var}(T_n) = \dfrac{n}{n-2}\).
- Lorsque \(n \to +\infty\), la loi \(\mathcal{T}_n\) converge vers \(\mathcal{N}(0,1)\).
- En pratique, pour \(n > 30\), on assimile \(\mathcal{T}_n\) à \(\mathcal{N}(0,1)\).
L’espérance \(E(T_n) = 0\) pour \(n \geq 2\) traduit la symétrie de la densité. La variance \(\dfrac{n}{n-2}\) est strictement supérieure à 1 (la variance de \(\mathcal{N}(0,1)\)), ce qui confirme que les queues de la loi de Student sont plus lourdes que celles de la loi normale. Lorsque \(n\) croît, \(\dfrac{n}{n-2} \to 1\) : la loi de Student se rapproche de la loi normale, les queues s’amincissent progressivement. Pour \(n = 1\), on obtient la loi de Cauchy (dont l’espérance n’existe pas) ; pour \(n \leq 2\), la variance est infinie. Les valeurs de la fonction de répartition de \(\mathcal{T}_n\) sont tabulées (voir la table de Student).
Exercice 18
Deux machines 1 et 2 produisent un aliment en quantités horaires \(X_1\) et \(X_2\) (en kg) indépendantes, avec : \[X_1 \sim \mathcal{N}(50{,}2\;;\; 0{,}04), \qquad X_2 \sim \mathcal{N}(50{,}1\;;\; 0{,}09).\]
On pose \(D = X_2 - X_1\).
- Déterminer la loi de \(D\).
- Calculer \(P(X_2 > X_1)\).
\(X_1\) et \(X_2\) étant indépendantes et normales, leur différence est encore normale.
1. \(D = X_2 - X_1 \sim \mathcal{N}(m_D,\, \sigma_D^2)\) avec : \[m_D = 50{,}1 - 50{,}2 = -0{,}1, \qquad \sigma_D^2 = 0{,}09 + 0{,}04 = 0{,}13.\] Donc \(D \sim \mathcal{N}(-0{,}1\;;\; 0{,}13)\) et \(\sigma_D = \sqrt{0{,}13} \approx 0{,}361\).
2. On cherche \(P(X_2 > X_1) = P(D > 0)\).
En standardisant : \[P(D > 0) = P\!\left(Z > \frac{0 - (-0{,}1)}{0{,}361}\right) = P(Z > 0{,}28) = 1 - \Phi(0{,}28) \approx 1 - 0{,}6103 = 0{,}390.\]
La machine 2 produit plus que la machine 1 dans environ 39 % des cas.
Exercice 19
Soit \(X \sim \mathcal{N}(0,1)\) et \(\lambda \in \mathbb{R}\). Calculer la transformée de Laplace \(E\!\left(e^{\lambda X}\right)\).
En déduire \(E\!\left(e^{\lambda X}\right)\) pour \(X \sim \mathcal{N}(m, \sigma^2)\).
Dans un modèle financier, le cours d’une action à la date \(T\) est : \[S_T = S_0\, e^{Z}, \qquad Z \sim \mathcal{N}(\mu T,\, \sigma^2 T),\] où \(S_0 > 0\) est le cours spot. Quelle condition sur \(\mu\) et \(\sigma\) assure que \(E(S_T) = S_0\) ? Calculer alors \(\mathrm{Var}(S_T)\) en fonction de \(\sigma\), \(T\) et \(S_0\).
1. Pour \(X \sim \mathcal{N}(0,1)\) : \[E\!\left(e^{\lambda X}\right) = \int_{-\infty}^{+\infty} e^{\lambda x} \frac{1}{\sqrt{2\pi}} e^{-x^2/2}\,dx = \frac{1}{\sqrt{2\pi}} \int_{-\infty}^{+\infty} e^{-(x^2 - 2\lambda x)/2}\,dx.\]
On complète le carré : \(x^2 - 2\lambda x = (x - \lambda)^2 - \lambda^2\), donc : \[E\!\left(e^{\lambda X}\right) = e^{\lambda^2/2} \cdot \frac{1}{\sqrt{2\pi}} \int_{-\infty}^{+\infty} e^{-(x-\lambda)^2/2}\,dx = e^{\lambda^2/2}.\]
\[\boxed{E\!\left(e^{\lambda X}\right) = e^{\lambda^2/2}}\]
2. Pour \(X \sim \mathcal{N}(m, \sigma^2)\), on écrit \(X = m + \sigma Z\) avec \(Z \sim \mathcal{N}(0,1)\) : \[E\!\left(e^{\lambda X}\right) = E\!\left(e^{\lambda(m + \sigma Z)}\right) = e^{\lambda m}\,E\!\left(e^{\lambda\sigma Z}\right) = e^{\lambda m + \lambda^2\sigma^2/2}.\]
\[\boxed{E\!\left(e^{\lambda X}\right) = e^{\lambda m + \lambda^2\sigma^2/2}}\]
3. On a \(S_T = S_0 e^Z\) avec \(Z \sim \mathcal{N}(\mu T,\, \sigma^2 T)\).
En utilisant la question 2 avec \(\lambda = 1\), \(m = \mu T\), \(\sigma^2 = \sigma^2 T\) : \[E(S_T) = S_0\,E(e^Z) = S_0\,e^{\mu T + \sigma^2 T/2}.\]
La condition \(E(S_T) = S_0\) impose : \[e^{\mu T + \sigma^2 T/2} = 1 \implies \mu T + \frac{\sigma^2 T}{2} = 0 \implies \boxed{\mu = -\frac{\sigma^2}{2}}.\]
Variance : \(\mathrm{Var}(S_T) = E(S_T^2) - E(S_T)^2\).
On a \(S_T^2 = S_0^2\, e^{2Z}\), donc avec \(\lambda = 2\) : \[E(S_T^2) = S_0^2\,e^{2\mu T + 2\sigma^2 T}.\] Sous la condition \(\mu = -\sigma^2/2\) : \[E(S_T^2) = S_0^2\,e^{-\sigma^2 T + 2\sigma^2 T} = S_0^2\,e^{\sigma^2 T}.\] Donc : \[\boxed{\mathrm{Var}(S_T) = S_0^2\!\left(e^{\sigma^2 T} - 1\right)}.\]
Exercice 20 — Règle empirique (trois sigma)
Soit \(X \sim \mathcal{N}(m, \sigma^2)\).
- Montrer que \(P(|X - m| < \sigma) \approx 0{,}683\).
- Montrer que \(P(|X - m| < 2\sigma) \approx 0{,}954\).
- Montrer que \(P(|X - m| < 3\sigma) \approx 0{,}997\).
- En déduire la probabilité d’observer une valeur située au-delà de \(3\sigma\) de la moyenne.
Par standardisation, \(Z = (X-m)/\sigma \sim \mathcal{N}(0,1)\), et \(P(|X-m| < k\sigma) = P(|Z| < k) = 2\Phi(k) - 1\).
1. \(P(|X-m| < \sigma) = 2\Phi(1) - 1 = 2 \times 0{,}8413 - 1 = 0{,}6826 \approx 68{,}3\,\%\).
2. \(P(|X-m| < 2\sigma) = 2\Phi(2) - 1 = 2 \times 0{,}9772 - 1 = 0{,}9544 \approx 95{,}4\,\%\).
3. \(P(|X-m| < 3\sigma) = 2\Phi(3) - 1 = 2 \times 0{,}9987 - 1 = 0{,}9974 \approx 99{,}7\,\%\).
4. \(P(|X-m| \geq 3\sigma) = 1 - 0{,}9974 = 0{,}0026\), soit environ \(0{,}26\,\%\) (1 chance sur 385).
Exercice 21 — Intervalle optimal de largeur fixée
Soit \(X \sim \mathcal{N}(m, \sigma^2)\) et \(b > 0\) une largeur fixée.
On cherche l’intervalle \(]x,\; x+b[\) qui maximise \(P(x < X < x+b)\).
- Exprimer \(P(x < X < x+b)\) en fonction de \(\Phi\), \(m\), \(\sigma\) et \(x\).
- Montrer que le maximum est atteint lorsque l’intervalle est centré en \(m\), c’est-à-dire \(x = m - b/2\).
- En déduire la valeur maximale de \(P(x < X < x+b)\).
1. \(P(x < X < x+b) = \Phi\!\left(\dfrac{x+b-m}{\sigma}\right) - \Phi\!\left(\dfrac{x-m}{\sigma}\right)\).
2. On dérive par rapport à \(x\) et on annule : \[\frac{d}{dx}\left[\Phi\!\left(\frac{x+b-m}{\sigma}\right) - \Phi\!\left(\frac{x-m}{\sigma}\right)\right] = \frac{1}{\sigma}\left[\varphi\!\left(\frac{x+b-m}{\sigma}\right) - \varphi\!\left(\frac{x-m}{\sigma}\right)\right] = 0,\] où \(\varphi\) est la densité de \(\mathcal{N}(0,1)\).
On a \(\varphi(u) = \varphi(v) \iff |u| = |v|\). Comme \(b > 0\), les deux arguments ne sont pas égaux, donc : \[\frac{x+b-m}{\sigma} = -\frac{x-m}{\sigma} \implies 2x + b = 2m \implies x = m - \frac{b}{2}.\]
On vérifie que c’est un maximum (la dérivée seconde est négative en ce point).
3. En substituant \(x = m - b/2\) : \[\max P(x < X < x+b) = \Phi\!\left(\frac{b}{2\sigma}\right) - \Phi\!\left(-\frac{b}{2\sigma}\right) = 2\Phi\!\left(\frac{b}{2\sigma}\right) - 1.\]
Exercice de synthèse
La résistance à la rupture (en MPa) d’un matériau est modélisée par une variable aléatoire \(R\) de loi normale \(\mathcal{N}(250,15^2)\). On considère la charge appliquée par une machine, modélisée par \(C\sim\mathcal{N}(220,10^2)\), indépendante de \(R\).
- Calculer \(P(R<230)\).
- Déterminer le seuil \(s\) tel que \(P(R\geq s)=0{,}10\).
- On définit la marge de sécurité \(M=R-C\).
- Déterminer la loi de \(M\).
- Calculer \(P(M>0)\) et interpréter le résultat.
Cet exercice combine les trois usages principaux de la loi normale. Partie 1 : standardisation directe, puis lecture de \(\Phi\) (queue gauche). Partie 2 : lecture inverse — on réécrit \(P(R \geq s) = 0{,}10\) comme \(P(R \leq s) = 0{,}90\), puis on lit le quantile d’ordre \(0{,}90\) dans la table. Partie 3 : par indépendance, les variances de \(R\) et \(C\) s’additionnent (et non les écarts-types) pour obtenir la variance de \(M = R - C\) ; on standardise ensuite \(M\) pour exprimer \(P(M > 0)\) en termes de \(\Phi\).
Probabilité de résistance insuffisante \[P(R<230)=P\left(\frac{R-250}{15}<\frac{230-250}{15}\right)=P(Z<-1{,}33) \approx 0{,}0918.\]
Quantile à 90 % \[P(R\geq s)=0{,}10 \iff P(R\leq s)=0{,}90.\] Avec \(z_{0{,}90}\approx 1{,}28\), \[s=250+15\times 1{,}28\approx 269{,}2\ \text{MPa}.\]
Marge de sécurité
Comme \(R\) et \(C\) sont indépendantes et normales, \[M=R-C \sim \mathcal{N}(250-220,15^2+10^2)=\mathcal{N}(30,325).\] Donc \(\sigma_M=\sqrt{325}\approx 18{,}03\).
Alors \[P(M>0)=P\left(\frac{M-30}{18{,}03}>\frac{0-30}{18{,}03}\right) = P(Z>-1{,}66)=\Phi(1{,}66)\approx 0{,}9515.\]
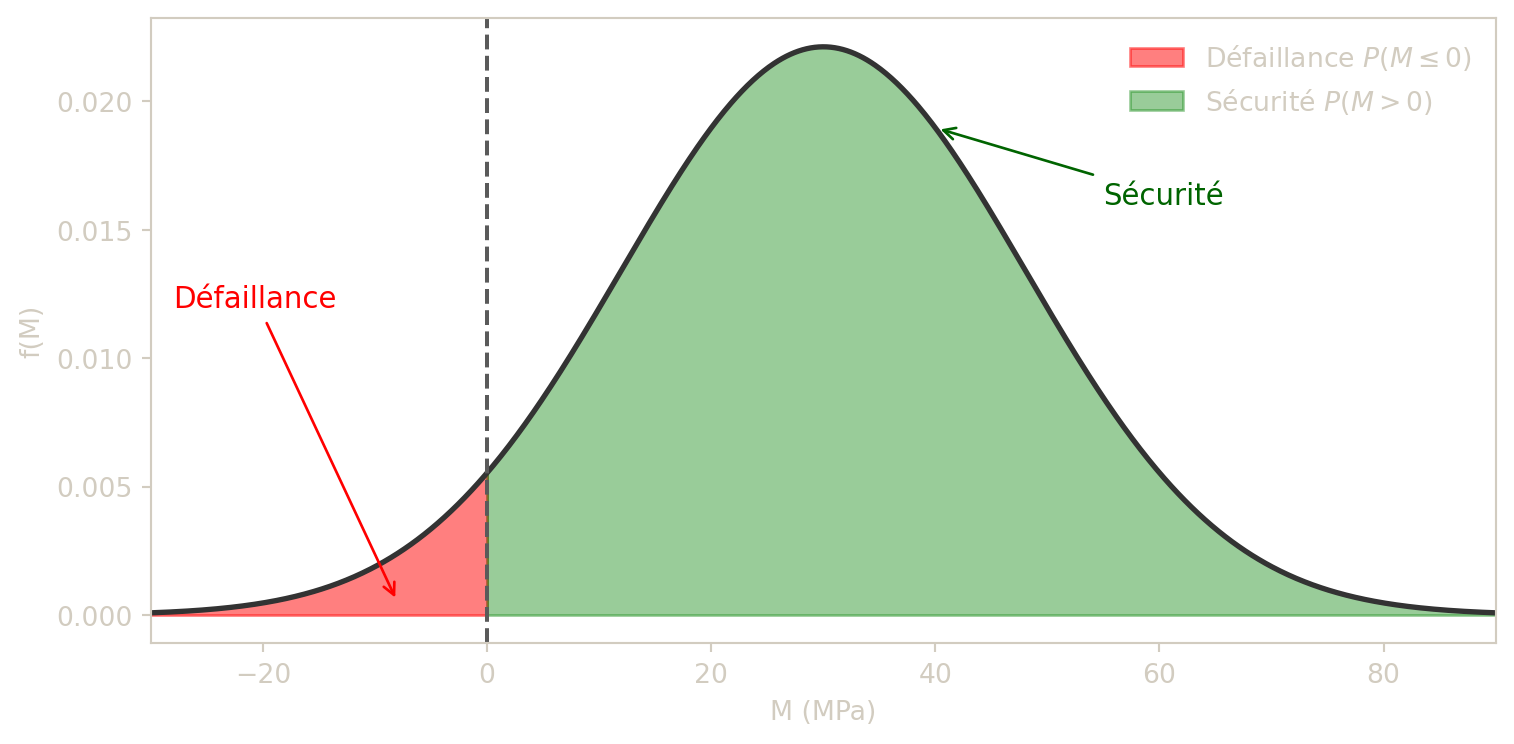
Interprétation : dans ce modèle, la résistance dépasse la charge dans environ 95 % des cas.
- La standardisation \(Z=(X-m)/\sigma\) est la clé de presque tous les calculs sur les lois normales.
- La règle empirique (68–95–99,7) donne un repère mental immédiat sur la dispersion autour de la moyenne.
- La loi normale est stable par somme de variables indépendantes.
- Les lois log-normale et khi-deux se construisent directement à partir de la loi normale.
- La loi de Student intervient dès que l’on remplace \(\sigma\) par un estimateur ; elle converge vers \(\mathcal{N}(0,1)\) pour \(n > 30\).
- Les quantiles (lecture inverse) sont indispensables pour fixer des seuils de risque.